

Why do Hash Lookups?
Looking up cryptographic hashes of files is done for various reasons. The first and most common reason is to verify the integrity of a particular file. This is demonstrated in practically every Linux distro download on the web (this is especially vital to prevent headaches arising from corrupted downloads of the ISO file).
Another reason to do hash lookups, in the context of information security, is to determine if a file is known to be verified and safe or known to be malicious. This is done by checking a file’s cryptographic hash value against various databases. Some of the known databases include the National Software Reference Library (NSRL) set, VirusTotal, and ThreatCrowd
While including various intelligence sources, it’s tedious enough to look up one hash against multiple sources, much less thousands of files found in one disk image.
FileIntel to the Rescue!
To deal with this problem you can use the Python tool, FileIntel. According to FileIntel’s README, “This is a tool used to collect various intelligence sources for a given file. Fileintel is written in a modular fashion so new intelligence sources can be easily added.”
Here is the sample help output when the application is first run
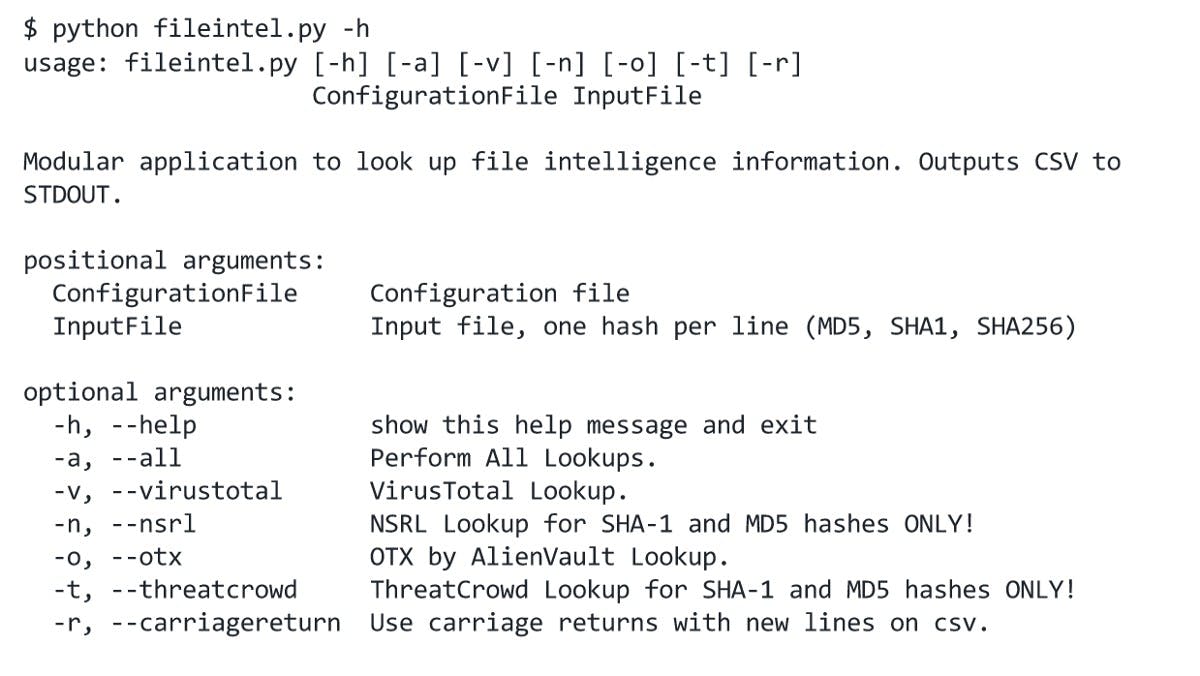
Help prompt
Currently, it supports lookups to the NSRL set, VirusTotal, ThreatCrowd, OTX, and ThreatExpert out of the box. The code also makes it easy to add more modules to the application.
FileIntel uses a configuration file to configure the various available modules. Note that for NSRL lookups to work, the “minimal” zip file must be downloaded from here and the path to the zip file nust me configured properly.

For easy testing, sample input is already given in the Github repo.
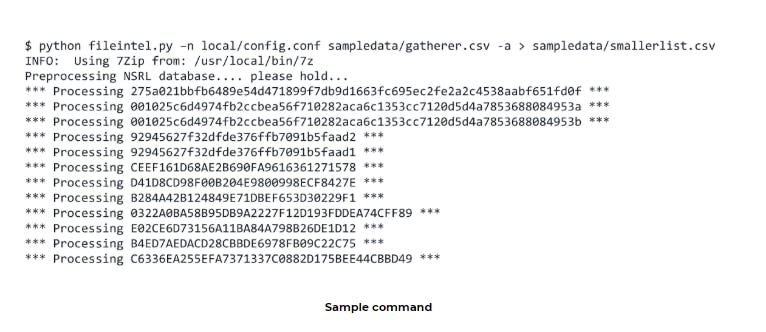
The results are then exported to a CSV file that can be easily read and used by any application that supports them.
FileIntel Issues and Solutions
FileIntel is a very nifty tool, but it is not without issues. For example, it streamlines the lookup process but it’s still slow due to the sheer number of hashes it has to check. It took almost 5–6 hours to process hashes from a 2GB E01 image. This is most likely due to the fact that it only uses a single thread to run the program.
A blogger named Mark JX was able to cut down the lookup process by eliminating a lot of the hashes to lookup while using parallel grep commands. The challenge now is figuring out how to integrate these performance-optimizing techniques in FileIntel.
Additionally, in the case of the NSRL set, preprocessing (which takes a very long time) happens every time FileIntel is utilized. This can be mitigated by modifying the code such that it only does preprocessing once, but research is still being completed.
With these modifications, FileIntel can prove to be a formidable lookup tool that combines speed and efficiency which is especially true when including powerful hardware.
